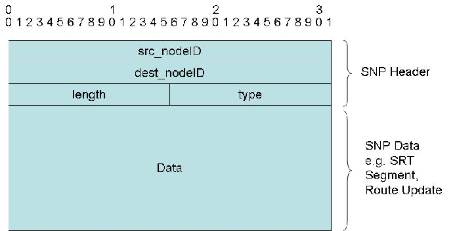
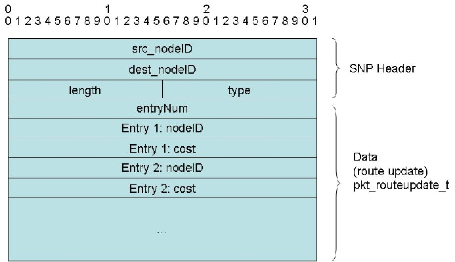
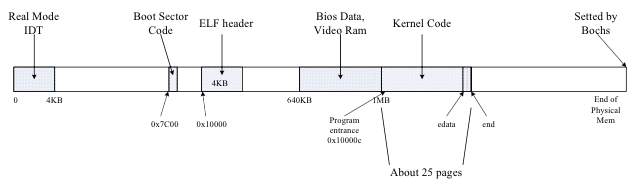
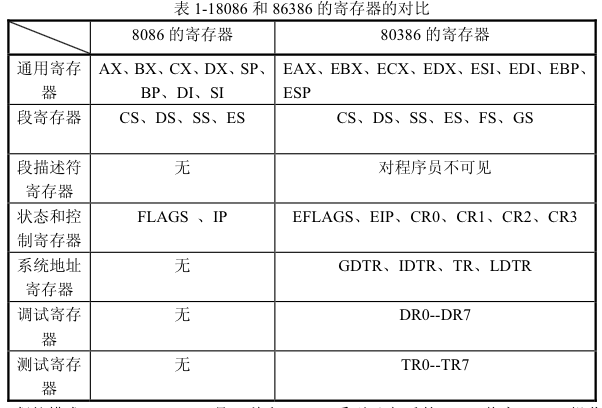
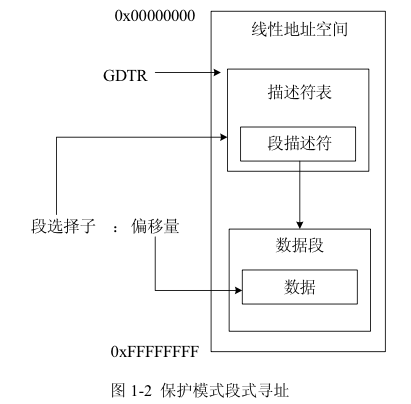
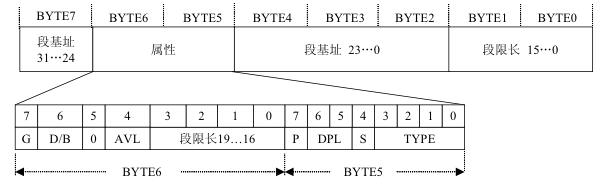
背景
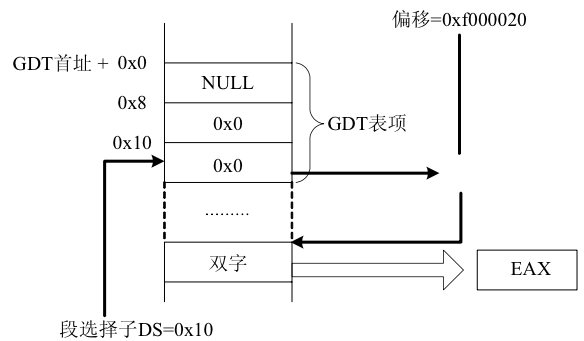
在boot/boot.S文件中,引入了一个全局描述符表,这个表把所有的段的基址设置为0,界限设置为0xffffffff=4GB的方式,关闭了分段管理的功能。因此虚拟地址中的段选择子字段的内容没有意义,线性地址的值总是等于虚拟地址中段内偏移的值
gdt:
SEG_NULL # null seg
SEG(STA_X|STA_R, 0x0, 0xffffffff) # code seg
SEG(STA_W, 0x0, 0xffffffff) # data seg
虚拟地址,线性地址与物理地址
虚拟地址(Virtual Address)是由两部分组成:段选择子(segment selector)和段内偏移(segment offset)
线性地址(Linear Address)指的是通过段地址转换机制把虚拟地址进行转换之后得到的地址
物理地址(Physical Addresses)是分页地址转换机制把线性地址进行转换之后得到的真实的内存地址
逻辑地址:虚拟地址中的段内偏移
整个流程是虚拟地址先经过分段机制转化成线性地址,之后再通过分页机制转化为物理地址。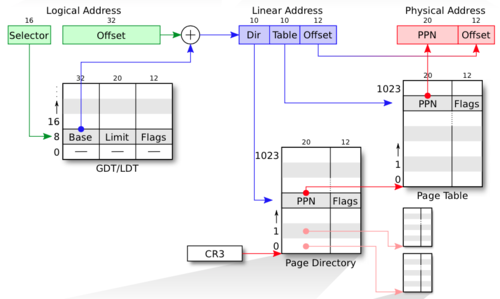
一旦进入保护模式,我们就不能直接使用线性地址或者物理地址了。所有代码中的地址引用都是虚拟地址的形式,然后被MMU系统所转换,所以C语言中的指针其实都是虚拟地址
页表管理机制
管理页表相关的函数:
- pgdir_walk()
- boot_map_region()
- page_lookup()
- page_remove()
- page_insert()
JOS中采用的是二级页表结构,根据va高10位得到页目录表项,从一级页表里得到页表物理地址,再根据va接下去的10位得到页表表项,得到页物理地址,最后根据最后12位页内偏移,得到最终的物理地址
为了方便我们实现页表管理,inc/mmu.h提供了几个有用的宏来帮助我们操作地址:
PGNUM(la):物理地址的页号
PDX(la):线性地址的页目录表项
PTX(la):线性地址的页表表项
PGOFF(la):线性地址的页内偏移
PTE_ADDR(pte):页表表项/页目录表项的物理地址
由于现在还没通过%cr3激活页表,因此现在的地址映射依然是之前的[KERNBASE, KERNBASE + 4MB)到[0, 4MB)。为了方便实现当前物理地址、页信息结构 、虚拟地址之间的转换,kern/pmap.h中也提供了一些有用的宏和函数:
PADDR(kva):虚拟地址对应的物理地址
KADDR(pa):物理地址对应的虚拟地址
page2pa(pp):页结构pp所对应的物理页地址
page2kva(pp):获取页结构pp对应的虚拟地址
pa2page(pa):物理地址所在的物理页的页结构pp
页面管理函数的实现
其实我们只需页面插入与页面删除两个函数即可实现页面管理的工作,下面通过函数原型,函数功能,以及函数实现三个方面来一一分析页面管理函数。
pgdir_walk()函数
函数原型:pgdir_walk(pde_t pgdir, const void va, int create)
函数功能:返回线性地址对应的页表项(PTE)的虚拟地址
create 标志是1,如果当前va地址所属的页不存在,那么申请开辟这页
create 标志是0,仅仅是查询va地址所属的页是否存在。存在就返回对应的page table的入口地址,不存在就返回NULL
pte_t * pgdir_walk(pde_t *pgdir, const void * va, int create)
{
unsigned int page_off;
pte_t * page_base = NULL;
struct PageInfo* new_page = NULL;
unsigned int dic_off = PDX(va);
pde_t * dic_entry_ptr = pgdir + dic_off;
if(!(*dic_entry_ptr & PTE_P))
{
if(create)
{
new_page = page_alloc(1);
if(new_page == NULL) return NULL;
new_page->pp_ref++;
*dic_entry_ptr = (page2pa(new_page) | PTE_P | PTE_W | PTE_U);
}
else
return NULL;
}
page_off = PTX(va);
page_base = KADDR(PTE_ADDR(*dic_entry_ptr));
return &page_base[page_off];
}
boot_map_region()函数
函数原型:static void boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
函数功能:完成虚拟地址到物理地址的映射过程,将虚拟地址空间范围[va, va+size)映射到物理空间[pa,pa+size)的映射关系加入到页表中
这个函数主要的目的是为了设置虚拟地址UTOP之上的地址范围,这一部分的地址映射是静态的,在操作系统的运行过程中不会改变,这些页PageInfo的pp_ref域的值不会改变
在每一轮中,把一个虚拟页和物理页的映射关系存放到响应的页表项中。直到把size个字节的内存都分配完。
static void boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
int nadd;
pte_t *entry = NULL;
for(nadd = 0; nadd < size; nadd += PGSIZE)
{
entry = pgdir_walk(pgdir,(void *)va, 1); //Get the table entry of this page.
*entry = (pa | perm | PTE_P);
pa += PGSIZE;
va += PGSIZE;
}
}
page_insert()函数
函数原型:page_insert(pde_t pgdir, struct PageInfo pp, void *va, int perm)
函数功能:物理内存中页pp与虚拟地址va建立映射关系
如果va所在的虚拟内存页不存在,那么pgdir_walk的create为1,创建这个虚拟页。如果va所在的虚拟内存页存在,那么取消当前va的虚拟内存页也和之前物理页的关联,并且为va建立新的物理页联系
pp->pp_ref++语句需要放在page_remove之前,在虚拟内存页已经存在的情况,pp被释放,从而导致无法访问。
int page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
pte_t *entry = NULL;
entry = pgdir_walk(pgdir, va, 1); //Get the mapping page of this address va.
if(entry == NULL) return -E_NO_MEM;
pp->pp_ref++;
if((*entry) & PTE_P) //If this virtual address is already mapped.
{
tlb_invalidate(pgdir, va);
page_remove(pgdir, va);
}
*entry = (page2pa(pp) | perm | PTE_P);
pgdir[PDX(va)] |= perm; //Remember this step!
return 0;
}
page_lookup()函数
函数原型:struct PageInfo page_lookup(pde_t pgdir, void va, pte_t *pte_store)
函数功能:根据虚拟地址va返回它映射的物理页信息
调用pgdir_walk函数获取这个va对应的页表项,然后判断这个页是否已经在内存中,如果在则返回这个页的PageInfo结构体指针。并且把这个页表项的内容存放到pte_store中。
疑问:pte_store设置成二级指针的意义何在?
struct PageInfo * page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
pte_t *entry = NULL;
struct PageInfo *ret = NULL;
entry = pgdir_walk(pgdir, va, 0);
if(entry == NULL)
return NULL;
if(!(*entry & PTE_P))
return NULL;
ret = pa2page(PTE_ADDR(*entry));
if(pte_store != NULL)
{
*pte_store = entry;
}
return ret;
}
page_remove()函数
函数原型:void page_remove(pde_t pgdir, void va)
函数功能:取消虚拟地址va对应的物理页的映射关系
利用page_lookup()找到这个物理页使它无效,同时要将tlb中的对应条目无效。pp_ref减一,*pte = 0;将此页对应的页表项置0,页面回收
void page_remove(pde_t *pgdir, void *va)
{
pte_t *pte = NULL;
struct PageInfo *page = page_lookup(pgdir, va, &pte);
if(page == NULL) return ;
page_decref(page);
tlb_invalidate(pgdir, va);
*pte = 0;
}